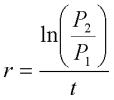
Base de Datos de Población de América Latina y El Caribe (ALC).
Los usuarios de esta Base de Datos deben tener como referencia la siguiente fuente de información:
Centro Internacional de Agricultura Tropical (CIAT), United Nations Environment Program (UNEP), Center for International Earth Science Information Network (CIESIN), Columbia University, and The World Bank (2005) Latin American and Caribbean Population Data Base. Version 3, disponible en http://www.na.unep.net/datasets/datalist.php3 ó http://gisweb.ciat.cgiar.org/population/esp/conjunto_datos.htm
Contacto: Glenn Hyman
La población de América Latina y El Caribe, registró un incremento de 340 millones de habitantes entre 1950 y el 2000, pasando de 175 millones a 515. ¿Dónde se dió este crecimiento? ¿Cuál es la magnitud del cambio en las diferentes zonas? ¿Cómo podemos visualizar las dimensiones del cambio geográfico de la población de América Latina y El Caribe? Nosotros recopilamos censos y otros datos de dominio público para analizar, tanto los cambios temporales como los poblacionales en la región. Nuestra base de datos incluye totales de población para más de 18300 distritos administrativos dentro de la América Latina y El Caribe. Las tablas de los censos fueron enlazadas a los mapas con las divisiones administrativas de la región y manejadas en un sistema de información geográfica. Nosotros transformamos los mapas vector de población a superficies 'raster', para lograr así los mapas digitales que nos permitieran hacer comparaciones con otros tipos de información geográfica de uso frecuente. Se hizo la validación y análisis con el fin de chequear posibles errores en los datos y compararlos con otras bases de datos que tenían fuentes de información diferentes. Los mapas digitales de población producidos en este proyecto, han sido puestos a disposición del público y pueden ser descargados desde nuestro sitio en la red. Los mapas de América Latina y El Caribe, hacen parte de un gran esfuerzo multi-institucional para el mapeo de población en todo el mundo. Esta es la tercera versión de la Base de Datos de Población de América Latina y El Caribe y contiene nuevos datos de los censos del 2000, además de nuevas y mejores superficies de accesibilidad para la creación de los mapas tipo 'raster'.
El proyecto de la Base de Datos de Población para América Latina y El Caribe contribuye a lograr la meta que tienen varias organizaciones de investigación y desarrollo de proporcionar mapas digitales de población para la mayoría de países en desarrollo en la región. Este proyecto se ciñe, en la medida de lo posible, al diseño y metodología del desarrollado previamente con las bases de datos de Asia y África (Deichmann 1994, Deichmann 1996a). La base de datos ha sido actualizada con relación a las versiones previas que fueron publicadas en el clearinghouse del Programa del Medio Ambiente de las Naciones Unidas (UNEP 2000). Los nuevos mapas incluyen información reciente de datos censales del 2000, para 16 países. Nosotros mejoramos la resolución espacial de los nuevos mapas, recolectando datos mas detallados a nivel administrativo para varios países, incrementando sustancialmente el número de unidades administrativas con relación a las versiones previas.
Incluimos información sobre las fuentes de datos población y de las divisiones administrativas, procedimientos para la recolección de los datos y algunos indicadores de la calidad de los mismos. La documentación de los métodos para la creación de los mapas se deriva de los recientes trabajos en África y en Asia. Las superficies raster de población están basadas en un archivo de datos de más de 18300 unidades administrativas y 10700 centros poblados. Se usaron tasas de crecimiento demográfico para proyectar los totales de población, desde las fechas de los censos de cada país hacia atrás (1950) y hacia adelante (2000). Esta documentación incluye también apéndices con información sobre la resolución y calidad de los datos y las fuentes de información sobre los datos de población y los límites administrativos.
La información para la base de datos de límites administrativos y de población para América Latina y El Caribe, fue recopilada de mapas de escala media a nivel nacional y sub-nacional, censos nacionales de población y de datos de las Naciones Unidas para las islas pequeñas del Caribe. La información censal de los principales países latinoamericanos, de Cuba, Puerto Rico, Jamaica, Trinidad y Tobago, Haití y República Dominicana, fueron tomados de los censos de población de cada país. La mayoría de los mapas con las divisiones administrativas para los países latinoamericanos y de las grandes islas caribeñas, fueron digitalizados en el Centro Internacional de Agricultura Tropical (Jones and Bell 1997) y los restantes fueron adquiridos en las agencias gubernamentales de cada país. Las naciones isleñas más pequeñas del Caribe, carecen de unidades administrativas sub-nacionales. Los límites de estos países fueron tomados del Digital Chart of the World. Ninguno de los datos de límites o de población, ha sido chequeado oficialmente o respaldado por los Institutos Nacionales de Estadística, los Institutos Geográficos Nacionales o por las Naciones Unidas.
Nuestro trabajo en este proyecto de mapeo de población avanzó de manera paralela con el desarrollo del proyecto de "Gridded Population of the World", versión 3 (GPW3). Todos los autores han estado involucrados en algunos de los aspectos del GPW3 (CIESIN y CIAT, 2004). La mayoría de los chequeos de los datos de población fueron llevados a cabo en el contexto del proyecto GPW3. Los puntos establecidos en el desarrollo del GPW3 fueron utilizados en el desarrollo de los medelos de accesibilidad y subsecuentemente usados en la conversion de mapas poblacionales de vector a superficies 'raster' (CIESIN et al.,2004) .
La escala de los
mapas fuente varía de 1:50000 a 1:1125000. La mayoría de estos
límites fueron digitalizados en los años 90 de copias en papel
de mapas publicadas en los años 80 y 90. En algunos casos, nosotros adquirimos
los mapas con las divisiones administrativas directamente de los institutos
geográficos nacionales o de las oficinas de censos. Los usuarios de los
mapas digitales de población deberán tener en mente la considerable
diferencia en escala y calidad de los mapas que sirvieron de base para los límites.
La calidad de los datos para límites futuros, deberá incrementarse
con mejoras en la capacidad al interior de los institutos de geográficos
y de censos. Futuros esfuerzos deberán basarse en la información
de límites que sea producida, verificada y respaldada por los correspondientes
institutos en los diferentes países. El apéndice 4 incluye información
detallada sobre los datos de límites que se utilizaron en esta base de
datos, para cada país.
Con el fin de asegurarnos
la mayor coincidencia posible entre los distintos mapas nacionales y para obtener
la máxima compatibilidad con otros archivos de datos de resoluciones
estándares promedio, todos los límites nacionales y costeros fueron
reemplazados con los patrones de límites (PONET) del Digital
Chart of the World (DCW). El DCW es un grupo de capas de datos básicos
digitales SIG, con una escala nominal de 1:1 millón. El uso de patrones
internacionales de límites muy detallados para, en algunos casos datos
de muy pobre resolución, no tiene mucho sentido pero es un requerimiento
para asegurarnos la coincidencia necesaria entre los mapas nacionales. En cualquier
aplicación de límites administrativos, debe tenerse en mente la
escala cartográfica más pequeña (de más pobre resolución),
en comparación con los patrones internacionales y costeros.
En unos pocos países, datos muy detallados de límites estuvieron disponibles para los cuales la información sobre referencias espaciales no eran conocidas. A la luz de los objetivos de este proyecto, esto nunca fue incorporado con el fin de lograr la máxima resolución. No obstante, la transformación ad hoc, el cambio de proyección y el ajuste entre escalas requerido para conseguir que estos datos fueran compatibles con los patrones del DCW, indujeron sin duda alguna, a introducir un error de posición que bien podría alcanzar una magnitud de 1-2 km.
Con unas pocas
excepciones, nosotros usamos cifras oficiales de censos o estimaciones oficiales,
las cuales fueron tomadas directamente de publicaciones nacionales (reportes
censales o informes anuales estadísticos) o de fuentes secundarias de
datos (informes anuales y gaceteros). Los datos fueron tomados de censos de
los años 90 y más recientemente de censos de alrededor del 2000.
Varios países en la región tienen nuevos datos que hasta ahora
no han sido dados a la luz pública y esperamos poder actualizar nuestro
mapa cuando dispongamos de esta nueva información. Las fuentes específicas
de información poblacional, están indicadas para cada país
en el apéndice III.
La precisión
de los censos varía por país. Estuvo más allá del
enfoque de este proyecto, entrar a evaluar la precisión de los censos
o de los estimados oficiales que hizo cada país. Esto tal vez sería
posible si existieran, después de los censos, enumeraciones tales que
se pudiera con base en ellas estimar mejor la precisión. Nosotros comparamos
los totales por país con los de las bases de datos del Population
Reference Bureau (PRB) y con los de la Comisión Económica
para Amércia Latina y El Caribe (CEPAL). La CEPAL, el PRB y otras fuentes
que muestran totales por país, tienen cifras que probablemente están
muy cercanas al verdadero valor de la población en cada país.
Nuestros datos provienen de los censos de manera desagregada y no incorporan
este tipo de correciones. En aquellos países en los cuales existía
una diferencia de más del 5% con relación a los datos estimados
por Naciones Unidas (UN 2005), hicimos un ajuste para mantener la uniformidad
de nuestra información demográfica con la de ellos. En países
con sistemas de registro en buen funcionamiento, las cifras de población
alcanzan una precision bastante buena, de fracciones de uno por ciento. En los
Estados Unidos, las cifras censales muestran una precisión de alrededor
del 2%. Con algunas excepciones, la precisión para los censos en América
Latina es probablemente más baja.
La mayoría de países de América Latina tratan de programar sus censos al comienzo de cada década y con un intervalo de 10 años. Los datos de población están generalmente alrededor de fechas como 1990 o 2000, con una fecha censal promedio de 1996 y en varios de los casos, nuestros datos de límites difieren de los de población. La información tabular de población tiene más datos en términos de unidades administrativas que las que aparecen en los mapas de los límites, problema este que surgió debido a la creación de nuevos municipios después del último censo. Nosotros manejamos este problema país por país, tratando de encontrar las discrepancias y agregando luego los datos para los municipios que habían sido subdivididos.
Las proyecciones
de población fueron hechas país por país con base en los
censos llevados a cabo en 1960, 1970, 1980, 1990 y 2000. La mayoría de
las proyecciones se basaron en las tasas de crecimiento histórico de
la población, a nivel de departamento en América Latina y El Caribe.
El volúmen de artículos y monografías sobre los métodos
de proyecciones de población en la literatura demográfica, es
bastante grande. Coinciden, sin embargo, la mayoría de estas publicaciones
en enfatizar que estos métodos no tienen una precisión muy alta
para predecir la población en períodos no muy cortos de tiempo
(O'Neill y Balk 2001, véase una interesante discusión en Cohen,
1995).
En este proyecto, usamos los datos de tasas de crecimiento de la CEPAL, basados en la tendencia matemática de la predicción. En contraste con los estimados previos para proyectos globales demográficos, las cifras reales para cada unidad sub-nacional se basaron, para la mayoría de los países, en la tasa de crecimiento intercensal específica entre el último y el penúltimo censos. La tasa inter-censal de crecimiento viene dada por:
donde r es la tasa promedio de crecimiento anual, P1 y P2 son los totales de población para dos diferentes períodos de tiempo y t es el número de años entre los dos períodos (ver, ejemplo Rogers 1985). Las tasas de recimiento resultantes fueron utilizadas para hacer las estimaciones correspondientes a cada año. Por ejemplo, con base en los conteos de población de 1967 y 1977 y su correspondiente tasa de crecimiento r, la población para 1970 se estimó de la siguiente manera:
![]()
En los casos en
los cuales no se disponía de información para antes de 1960 y
después de 2000, la tendencia existente entre los dos conteos de población
más cercanos, fue usada para extrapolar los datos. De manera similar
las proyeciones de población más allá del 2000 se hicieron
usando las tasas promedio de crecimiento entre 1990 y 2000, como puede verse
en las bases de datos de GIS.
Para predicciones
basadas en información de unos pocos años, las tendencias de las
proyecciones matemáticas son usualmente bastante precisas y el tipo específico
de función utilizado tiene muy poca influencia sobre los resultados (Cohen
1995). Un enfoque más elaborado para hacer estimación, como por
ejemplo, el método cohort de supervivencia, podría arrojar
unos estimados más confiables, pero los requerimientos para el uso de
esta técnica, distribución de edades y sexo, asi como también
edad específica de nacimineto, muerte y las tasas de migración,
fueron aspectos que estuvieron lejos del alcance de este proyecto. Dado el método
utilizado para la predicción de la población, las características
de los datos disponibles tienen un impacto significativo.
Los estimados de
población son a lo mejor unos estimados no muy afinados, que deberían
ser interpretados dentro de unos márgenes de confianza bastante amplios.
En términos generales, podríamos esperar que la confiabilidad
de los estimados sea más baja mientras más larga sea la distancia
en tiempo entre los censos que se usan como base para el cálculo, - esto
quiere decir que los intervalos de confianza alrededor de los puntos estimados
llegan a ser mucho más amplios en la medida en que se incremente el tiempo
entre censos. Los datos para algunos países en los la información
estuvo disponible solamente para comienzos de los años 80, necesitan
ser mirados como un buen estimado únicamente.
Las cantidades
incluídas en la base de datos son tomadas directamente de los estimados
y por esto muestran más cifras significativas de las que justifican su
precisión. Durante el proceso y manipulación de los datos, uno
debería preservar todas las cifras significativas, pero para efectos
de la presentación, las cantidades deben ser redondeadas lo que refleja
alguna incertidumbre con los datos. Aún así, el uso de las cifras
de población en miles en nuestra tabla de arrriba, es claramente optimista.
Dadas las limitaciones en cantidad y calidad de la base de datos, nosotros chequeamos los totales nacionales resultantes contra algunas referencias estándar, como son los estimados que publican regularmente las Naciones Unidas. Obviamente que los datos están asociados ellos mismos con una considerable cantidad de incertidumbre, puesto que sus estimados se basan en predicciones condicionales que presentan un número de supuestos relacionados con fertilidad pasada y futura, mortalidad y tasas de migración. También ellos están basados, en buena parte, en cifras oficiales de los censos, las cuales han probado ser de poca confiabilidad. En los casos en los cuales nuestro estimado difería considerablemente del de las Naciones Unidas (NU), la tasa de crecimiento inter-censal fue ajustada uniformemente, de tal manera que el resultado estimado fuera igual o cercano al dato de las NU (Naciones Unidas 1998). Este es el caso típico en el cual los datos del último censo disponible son muy viejos o también es el caso de un país que experimenta una significativa reducción de la fertilidad en los años recientes, que no es reflejada adecuadamente en la dinámica de población entre los dos últimos censos. Los ajustes están indicados en la documentación específica de cada país (Apéndice I).
Varias excepciones
fueron hechas al uso general que le dimos a las tasas de crecimiento de la CEPAL
para hacer las proyecciones de población. En el caso de los 16 países
para los cuales tuvimos nuevos datos censales de alrededor del 2000, las proyecciones
para la última década fueron hechas a nivel de la información
disponible, usualmente a nivel de municipio. También usamos las tasas
de crecimieno de la CEPAL en las proyecciones de población de las grandes
islas caribeñas -- Cuba, Jamaica, Puerto Rico, Trinidad yTobago, Haití
y República Dominicana. Las proyecciones de población de las Naciones
Unidas (a nivel nacional), fueron usadas en nuestra base de datos para todos
los países pequeños del Caribe de los cuales no teníamos
datos de límites sub-nacionales (Naciones Unidas 1998). En unos pocos
casos adicionales, usamos tasas de crecimiento a nivel nacional para las proyecciones.
Las cifras de población de las Naciones Unidas fueron utilizadas para
calcular tasas de crecimiento demográfico en tres casos:
Dado nuestro limitado
conocimiento de la precisión de los datos originales, es imposible hacer
una determinación objetiva de la calidad de los mismos. La generación
de un índice de calidad para los datos de límites y de población
fue considerada dentro de este proyecto, pero dicho índice estaría
asociado con una serie de apreciaciones considerablemente subjetivas. Cualquier
inquietud en términos de "¿Qué tan buenos son los
datos?", es incompleta sin la pregunta, "¿Para qué propósito?".
Los datos que son claramente inapropiados para aplicaciones de alta resolución
a nivel de provincia o de sub-provincia, pueden ser suficientemente precisos
para ser utilizados en aplicaciones a escala continental o regional (que fue
la idea inicial de este proyecto), o para la visualización de patrones
espaciales de un país. Asi que, nosotros proporcionamos en la tabla de
abajo alguna información muy somera sobre las mediciones hechas y la
documentación referida a cada país en particular, brindando todos
los detalles conocidos acerca del origen de los datos (admitiendo que este conocimiento
es a menudo muy limitado). El usuario puede considerar esta información
y tomar su propia decisión sobre si los datos son los apropiados para
una tarea específica.
Al igual que en las anteriores bases de datos de esta misma naturaleza, nosotros incluimos en la tabla resumen del apéndice, dos mediciones que son muy útiles en cuanto a la resolución que tienen los datos:
Resolución Media en Km = (Área del país/Número
de Unidades) ^ 0.5
Ej.,la longitud de un lado de la unidad administrativa, si las unidades son cuadradas.
Población Media por unidad = total_población_nacional / número de unidades.
Estas dos mediciones se complementan muy bien entre sí. En países con grandes áreas deshabitadas, la resolución media en km da una impresión sesgada de que se dispone de mucho detalle. En tales casos, el número de personas por unidad es un indicador más significativo. A continuación se muestra la comparación entre Asia, África y América Latina, en cuanto a estas dos mediciones se refiere:
|
Resolución
Media en Km
|
Población
Media por unidad administrativa ('000)
|
|
|
Asia
|
117
|
1148
|
|
Africa
|
16 (32)1
|
7 (28)1
|
|
AL
|
33
|
29
|
1 Las cifras entre paréntesis son el dato de África cuando se descuentan las 83000 unidades de África del Sur, del total de 109268
Hay 18318 unidades administrativas con información de población en el archivo de datos. Mucha de la reducción de la resolución en kilómetros para América Latina y El Caribe es debida al alto nivel de detalle para el Brasil, que tiene cerca de la tercera parte del total de las unidades administrativas. Los datos de población para todos los países de América Latina fueron recolectados al más fino nivel de detalle posible. La reducción de la población media por unidad administrativa, refleja la alta resolución en kilómetros y, en comparación con Asia, más baja densidad de población.
El archivo de datos para América Latina y El Caribe fue preparado con diseño y metodología similares a las de los archivos de datos previamente desarrollados para África y Asia (Deichmann 1994, Deichmann 1996a). El proyecto demográfico global, en el Centro Nacional de Información Geográfica y Análisis (NCGIA), produjo un archivo de datos en formato grilla para el mundo entero el cual fue construido con una técnica de suavizado que tiene la propiedad de preservar los totales de población dentro de cada unidad administrativa (Tobler et al. 1995). Las superficies raster basadas en el enfoque de contornos de la siguiente sección, fueron construídas utilizando un método alternativo de interpolación. Este método mantiene los totales de población en cada distrito e incorpora información adicional sobre asentamientos humanos, infraestructura de transporte y otras características importantes que sirven para establecer la distribución de la población. La conversión de los datos de población de vector o polígono a formato raster, tiene la ventaja adicional de que los datos pueden ser combinados más fácilmente con archivos físicos espacialmente referenciados, que son a menudo almacenados en formatos de grilla. El formato raster facilita el uso de estos datos en investigación y en políticas de análisis y además contribuirá eficazmente en el fortalecimiento del enfoque integrado de los problemas relacionados con la población, la cultura, el medio ambiente y la economía, como ha sido defendido, entre otros, por Cohen (1995). Los metodos descritos aqui, así como también los enfoques alternativos al modelaje espacial de la población, son discutidos en más detalle en Deichmann (1996b).
El supuesto básico que se tuvo en cuenta para la construcción de la distribución de las grillas raster de población en América Latina y El Caribe, fue el de que las densidades de población estaban fuertemente correlacionadas con la accesibilidad. En términos generales, la accesibilidad se define como la oportunidad relativa de interacción y contacto. Estas oportunidades son mayores en aquellos sitios donde hay mayor concentración de personas y donde la infraestructura de transportes está bien desarrollada. Dentro de cualquier área dada, nosotros por supuesto esperamos que la población pueda compartir mucho más el conocimiento en aquellas regiones de mayor accesibilidad, en comparación con las que no tienen una buena conexión con los grandes centros urbanos.
A continuación describiremos los pasos de que consta el método para el desarrollo de las grillas raster de población. El dato más importante con que alimentamos el modelo es el relacionado con la red de transporte, es decir carreteras, vías férreas y ríos navegables. La segunda componente de importancia es la información sobre centros urbanos. Los datos sobre localización y tamaño del mayor número posible de municipios y ciudades que puedan ser identificados, es recolectado y la información de estos asentamientos se enlaza con la red de transporte. Estos datos son usados luego para calcular un simple índice de accesibilidad para cada nodo en la red. Esta medida es la llamada 'potencial de población', que no es otra cosa que la suma del número de habitantes de las poblaciones ubicadas en las cercanías de los correspondiente nodos, ponderada por una función de distancia, en la cual se utiliza la distancia entre los nodos y no las distancias en línea recta. La siguiente figura ilustra el cómputo del índice de accesiblidad para un solo nodo.
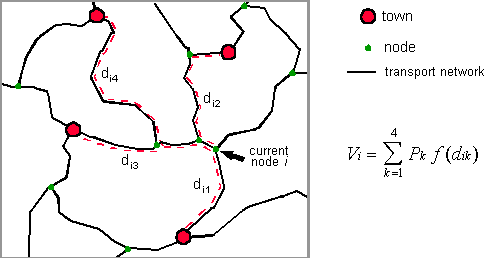
Los estimados de accesibilidad para cada nodo son subsecuentemente interpolados
sobre la superficie raster regular. Los datos raster de los cuerpos de agua
(lagos y glaciares), áreas protegidas y alturas, son utilizados luego
para ajustar las superficies de accesibilidad de una manera heurística.
Finalmente, los totales estimados de población para cada unidad administrativa
(como se describió en la primera parte de esta documentación),
son distribuidos proporcionalmente de acuerdo con los índices de accesibilidad,
en cada celda de la grilla. Las cifras de población resultantes en cada
pixel pueden luego convertirse en densidades poblacionales para análisis
adicionales y mapeo. Cada uno de estos pasos será descrito a continuación
en más detalle.
Existen pocas fuentes
de información que proporcionen capas de datos geográficos referenciados
y consistentes, para grandes áreas tales como un continente entero. La
infraestructura de datos de transporte para este proyecto, fue hecha usando
los siguientes archivos de datos: carreteras y vías férreas del
"Digital Chart of the World" (DCW), vías fluviales más
grandes y navegables del "World Boundary Data Bank II" (WBDII). El
WBDII se originó en la Agencia Central de Inteligencia de los Estados
Unidosy existe una versión 'Arc/Info" disponible en el "Environmental
Systems Research Institute", (ESRI). La escala nominal del WBDII es 1:3
millones. Puesto que nosotros también usamos el DCW en las capas para
los límites internacionales de las unidades administrativas y como consecuencia
de que WBDII y DCW tienen un origen común, hubo gran consistencia entre
las capas de datos a nivel individual.
El archivo de carreteras fue mejorado con la inclusión de algunas características de tipos de vías, tomadas de diferentes artículos y mapas digitales. Las carreteras fueron identificadas como sigue:
| Tipo de Carretera | Longitud Total en km(y % de todas las vías) | Estimado de la velocidad en (km/h) |
|---|---|---|
| Primarias (Autopistas/Vías principales) | 304,500 (22%) | 60 |
| Secundatrias (Permanentes/Vías con mejoras) | 300,000 (21%) | 35 |
| Terciarias (Parcialmente mejoradas/Caminos destapados) | 802,000 (57%) | 25 |
| Other network types | ||
| Railroads | 120,000 | 40 |
| Navigable rivers | 265,000 | 10 |
| Auxillary arcs | 1,690,000 | 5 |
Una breve discusión de tipo técnico es necesaria en este momento
para clarificar la estructura de los datos de transporte. Después de
fundir las componentes individuales de la red de transporte dentro de una capa
de datos, no existen todavía conexiones entre las componentes individuales
(ej., carreteras y ríos). Para permitirle al modelo escoger los más
eficientes medios de transporte en cualquier punto de la red, es necesario encontrar
cuales son las intersecciones entre las capas individuales de datos de transporte.
Esta es una operación SIG estándar que resulta en una capa de
información compuesta de arcos (o enlaces) que representan ríos
y carreteras y son conectados por nodos. Los nodos son intersecciones de dos
o más arcos de diferente o similar tipo y representan, por supuesto,
el final de un arco que carece de conexiones.
El programa usado para calcular la accesibilidad produce un estimado para cada
nodo en la red. El inconveniente en una aplicación donde la red está
esparcida en una amplia zona radica en que no se deriva valor alguno para aquellas
áreas que no estén conectadas con la red. También, el DCW
incluye solamente aquellas características de transporte claramente importantes
que son relevantes a escalas cartográficas de 1:1 o 1:3 millones. Una
solución a este problema es calcular el índice de accesibilidad
para el centro de cada una de las celdas de la grilla, en la generación
del archivo raster de salida. De cada una de las celdas de la grilla, la distancia
a la más cercana de las formas de transporte es calculada y adicionada
a la red de distancias de las poblaciones más cercanas. Este enfoque
fue usado por Geertman y van Eck (1995).
Sin embargo, este enfoque no es muy realista para aquellos lugares en los cuales
el punto de acceso más cercano a la red de transporte es un punto que
se halla muy lejos de los centros urbanos. Otro punto de acceso a la red podría
estar mucho más allá de la celda en la grilla inicialmente, pero
mejor conectado a las poblaciones más grandes. Evaluar las diferentes
opciones de acceso a la red para cada celda de la grilla sería muy poco
práctico y nosotros escogimos entonces un enfoque muy diferente. En zonas
en que la red de transporte se encuentra muy dispersa, arcos auxiliares son
adicionados, los cuales pueden ser vistos como "rutas alimentadoras".
Esencialmente, esto implica que las personas que podrían estar viviendo
en estas áreas remotas están usando remolques o camiones para
alcanzar la ruta principal de la red de transporte y continuar después
su viaje a la ciudad más cercana a través de las rutas más
rápidas. El algoritmo automáticamente determina cual es la ruta
óptima de acceso a la red, en términos de minimizar el número
de viajes que haya que hacer.
Sería mucho más directo usar las distancias de la red de transporte
para el cálculo de la accesibilidad. Sin embargo, arcos que representan
diferentes modalidades de transporte, están asociados por completo con
diversas velocidades del mismo. Por ejemplo, un kilómetro recorrido por
una vía pavimentada tomará mucho menos tiempo que la misma distancia
en una vía fluvial. En lugar de la simple distancia, nosotros podríamos
en consecuencia, utilizar el tiempo acumulado de viaje para ponderar el cálculo
de la accesibilidad. Cada arco en la resultante red de transporte está
asociado con un estimado de la velocidad promedio de cada posible viaje. Asumimos
que las carreteras primarias permiten una velocidad de 60km/h, las secundarias
de 35 km/h y a las terciarias se les asignó una velocidad de 25 km/h.
Para las vías férreas se asumió una velocidad de 40 km/h,
10 km/h para los ríos navegables y 5 km/h para las rutas auxiliaries.
Para cada arco, nosotros calculamos la distancia real-mundial, en kilómetros.
Todas las capas de datos están referenciadas en cordenadas geográficas (latitud/longitud) y no hay un mapa de la proyección real-mundial de las distancias en todas las direcciones con la suficiente confiabilidad para regiones muy grandes. En consecuencia nosotros calculamos la longitud correcta de cada arco como la sumatoria del círculo de distancias de todos los segmentos individuales que integran un arco entre dos nodos. El tiempo que se toma para atravesar cada seción de la red de transporte, es simplemente la distancia en km, dividida por la velocidad de viaje asociada con un específico modo de transporte.
El índice de accesibilidad es la suma del total de población
de los lugares vecinos a una localidad dada, ponderada por el tiempo de viaje
en la red de transporte ("distancia") a dicha localidad. Los datos
de ubicación y tamaño de los centros urbanos, fueron proporcionados
por CIESIN y totalizaron 10700 ciudades con estimados de población para
el año 2000.
Los pueblos necesitan ser conectados a la red de transporte para hacer posible el cálculo del algoritmo que encuentra los sitios poblados más cercanos para cada nodo en la red. Todos los asentamientos fueron entonces asignados al nodo que se hallaba más cerca de su ubicación en la red.
Para el cálculo real de la accesibilidad, nosotros empleamos un único
programa escrito en lenguaje C. Este programa lee completamente la definición
de la red de transporte, que consiste en, (a) los identificadores de cada nodo
y el tamaño de la población de cada sitio que corresponde al nodo
- cero en la mayoría de los casos, lo que quiere decir que no hay ningún
pueblo localizado en el nodo-, y (b) los identificadores de los dos nodos que
definen cada arco, además del tiempo de viaje que se necesita para recorrer
el arco.
Una opción adicional permitida por el programa que era la de considerar
la dirección en la que se recorre el arco, no fue tenida en cuenta en
este caso. Esto implica que no hay "calles en una sola vía"
y que el tiempo de viaje es el mismo sin importar en que sentido se haga. Este
supuesto puede ser un poco flojo porque, por ejemplo, la velocidad a la que
se recorre un río no es la misma hacia arriba que hacia abajo, pero lo
que podemos ganar reflejando este aspecto real no compensa con el esfuerzo adicional
que hay que hacer para definir claramente estos detalles. No fue hecho ningún
otro supuesto adicional. Para movilizarse a través de la red, un viajero
imaginario puede cambiar su medio de transporte a voluntad. Esto no es muy realista,
porque cambiarse digamos de viajar en una carretera a un tren o a subirse a
un bote, son cambios asociados todos con demoras. Aún así, con
la mira puesta en mantener simple el modelo (y manejable el tiempo de proceso)
nosotros no introdujimos en él ningún castigo para cambios en
la modalidad de transporte. Sin embargo, se hizo una modificación importante
en la escena regional. Para cada arco que cruzara las fronteras internacionales,
el tiempo de viaje fue incrementado en 30 minutos, buscando reflejar los retrasos
que implican los cruces fronterizos. Este tiempo de viaje puede ser variable
dependiendo de las relaciones entre dos países vecinos. Esto podría
requerir de un juicio subjetivo o de información muy detallada sobre
la permeabilidad de las fronteras internacionales.
Para cada nodo, el programa puede ahora encontrar la ruta en la red que tome
menos tiempo de viaje, para cada uno de los pueblos que se le especifiquen.
En las condiciones iniciales del programa, todos los pueblos están al
alcance en un tiempo de viaje especificado por el usuario. No obstante, en áreas
donde las poblaciones se encuentran muy dispersas y el número de nodos
y el de arcos es grande, esto resulta en tiempos de recorridos inaceptables.
En lugar de esto, nosotros modificamos el programa para encontrar los cuatro
poblados más cercanos o menos, si el programa no los detecta con un tiempo
de viaje bastante generoso de entrada. Esto también hace que el índice
sea más comparable a través de grandes áreas, puesto que
las especificaciones anteriores traían como resultado un índice
de accesibilidad de algunas zonas densamente pobladas, basado en cincuenta o
más pueblos, mientras que otras regiones solo contenían dos o
tres.
Para el cálculo de la ruta más corta, el programa utiliza el
algoritmo estándar de Dijkstra. La sección del programa usado
para esta búsqueda es una versión modificada de una buena adaptación
del citado algoritmo, desarrollada por Tom Cova, que es un especialista en sistemas
de transporte SIG, en NCGIA. El algoritmo Dijkstra evalúa la estructura
de la red de transporte alrededor de una localidad específica y va alejándose
cada vez más y más. Para aplicaciones en las cuales solo es de
interés una pareja de origen-destino, esto es ineficiente y han sido
sugeridas varias modificaciones en el dato de la velocidad que se utiliza en
la búsqueda. Por el contrario, en nuestra aplicación el interés
está centrado en encontrar la ruta más corta a todas las poblaciones
vecinas y el "defecto" del algoritmo de Dikstra es realmente una ñapa.
Es así como el algoritmo ligeramente modificado "recolecta"
poblaciones a medida que va alejándose del nodo original. Una vez que
los cuatro poblados han sido encontrados y el programa ha determinado que todos
los arcos adicionales conectados no conducen a ningún otro poblado que
se halle más cerca que aquellos ya encontrados, la búsqueda finaliza
y la población de esas localidades y los tiempos de recorrido, se transfieren
a la sección del programa que hace el cálculo del índice
de accesibilidad.
Este índice es la suma de la población de los pueblos ponderada por una función exponencial negativa del tiempo de viaje ("distancia"), i.e,
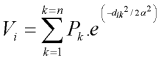
donde Vi es el estimado de accesibilidad para el nodo i, Pk es la población de un lugar específico k, dik es el tiempo de viaje/distancia entre el nodo i y el lugar k, y es la distancia al punto de inflexión de la función descendente. Este parámetro fue establecido en una hora para este caso, lo que quiere decir que la influencia de un sitio poblado que esté ubicado a más de una hora de distancia, decrece en alrededor del 60% y otro poblado ubicado a más de dos horas, solo contribuirá con el 14% de su población al cálculo del índice de accesibilidad. En lugar de utilizar los totales urbanos de población, nosotros aplicamos la transformación raiz cuadrada a los datos de población, lo que implica que una persona adicional que viva en una ciudad representa una influencia muy baja. Esta tranformación evita una exagerada influencia de las inmensas mega-ciudades y es menos compensadora que la muy común transformación logarítmica.
El índice de accesibilidadad que está disponible para cada uno
de los nodos de la red de transporte, necesita ser incorporado en una grilla
regular tipo raster. Nosotros usamos un procedimiento de interpolación
simple del inverso de la distancia, que tiene como resultado una superficie
suavizada. Un problema que se presenta con esta técnica es que los valores
interpolados no caerán fuera del rango de valores que tienen las localidades
vecinas de un mismo nodo. En analogía con la interpolación de
datos de elevación tenemos que: si los valores registrados están
disponibles únicamente para localidades ubicadas en la pendiente de la
montaña y no de la cima, el valor interpolado de una localidad dada resulta
ser subestimado. Recíprocamente en nuestra aplicación, si los
valores registrados son solamente para los nodos en la red, pero no para las
áreas lejanas de las rutas de transporte (ej. desiertos), entonces el
uso de los valores cercanos a los nodos de la red en la interpolación,
producirá una sobre-estimación de la accesibilidad para las localidades
remotas.
No obstante, experimentos con otros tipos de procedimientos para interpolación, no produjeron resultados satisfactorios. Interpolaciones de tipo no lineal (ej.: thin plate spline), podrían ser mucho más interesantes desde el punto de vista teórico, puesto que permitirían que los valores interpolados para una localidad dada pudieran caer por debajo o por encima de los datos registrados de localidades vecinas de un mismo nodo, si la presión global en la superficie sugiere que existe una tendencia definida. Sin embargo, los valores estimados para algunas localidades estuvieron claramente fuera del rango de lo que se considera razonable. Dado el gran número de nodos introducidos en remotas áreas por la adición de rutas de acceso auxiliaries, nosotros consideramos que el método de interpolación inverso de la distancia, nos brindaba suficiente precisión.
Tres archivos de datos adicionales fueron usados para ajustar los valores de
los indices de accesibilidad en la grilla: cuerpos de agua continentales, áreas
protegidas y datos de elevación. Los lagos fueron eliminados y a las
celdas de la grilla que caían en glaciares se les asignó un valor
de accesibilidad de cero. Esta información se sacó de la capa
de lagos del DCW.
La capa de datos SIG de áreas protegidas fue obtenida del World Conservation
Monitoring Center (WCMC). Infortunadamente, muy poca información
acerca de cada área protegida se logró conseguir mas allá
del nombre, de tal forma que fue imposible relacionar, por ejemplo, el grado
de protección en que se encuentra un área en particular, qué
tan deshabitada se encuentra y en qué se está utilizando. Nosotros
redujimos los índices de accesibilidad para aquellas celdas de la grilla
que cayeron dentro de los parques nacionales a 20% de su valor original. Estos
valores son determinados de una manera subjetiva y lo hacemos apoyados en el
hecho de que la protección en las áreas protegidas no siempre
es la mejor. Puesto que estos parques están ubicados en remotas regiones,
el cambio en las densidades de población predichas, que podría
ser introducido al variar los factores de ajuste, es realmente muy pequeño.
Zonas con alturas superiores a los 5000 metros fueron eliminadas del análisis. Muchas de estas áreas en los Andes, carecen de la condición de áreas protegidas, pero están deshabitadas. Nosotros no hicimos ajustes en zonas de menos de 2000 metros de altura. Entre 2000 y 5000 metros ponderamos los indices de accesibilidad con el criterio de que en áreas que tuvieran a más altura, tendrían menor índice de accesibilidad. Varias de las ciudades andinas más grandes están por encima de los 2000 metros sobre el nivel del mar, pero al incrementarse la altura, la densidad de población caía marcadamente.
La distribución del total de población de cada unidad administrativa
en las celdas de la grilla, se hacía de una manera muy directa cuando
la población caía dentro de dicha unidad administrativa. Los valores
estimados de accesibilidad para cada celda de la grilla, servían para
ponderar la distribución de una manera proporcional. Primero, los índices
de accesibilidad de las celdas en la grilla son sumados dentro de cada distrito.
Cada uno de los valores es dividido por la suma correspondiente a cada distrito,
de tal manera que los pesos resultantes sumen uno dentro de una unidad administrativa.
Multiplicando los valores de las celdas por el total de la población,
se obtiene el estimado del número de personas que residen en cada celda
de la grilla. La estandarización de los índices de accesibilidad
tiene como efecto que las magnitudes absolutas de los valores predichos de entrada,
no tengan mucha importancia y solamente la variabilidad dentro de la unidad
administrativa, determina las densidades de población dentro de cada
distrito.
Debemos tener en cuenta de nuevo el hecho de que todas las capas de datos SIG
y las grillas 'raster', son referenciadas por sus cordenadas (latitud/longitud).
Esto significa que las celdas en la grilla más allá de la línea
ecuatorial, representan un área real más pequeña que las
celdas en la grilla que se hallan más cerca de ella. Por ejemplo, una
celda en la grilla con 2.5 minutos tiene un área real de 10.8 km cuadrados
a 60 grados de latitud, 18.6 km cuadrados a 30 grados de latitud y en el Ecuador
tendría 21.4 km cuadrados. En consecuencia nosotros ponderamos el valor
del índice de accesibilidad para cada celda en la grilla, por área
real de dicha celda en la grilla, antes de estandarizar los valores dentro de
cada distrito.
Debido a que únicamente las magnitudes relativas del índice de
accesibilidad son importantes en la distribución total de la población
y puesto que la mayoría de las unidades administrativas son muy pequeñas,
el error introducido por la distorsión del sistema de cordenadas geográficas
usualmente es insignificante. Sin embargo, en aquellas zonas donde se disponía
de una resolución pobre, la verdadera diferencia de áreas entre
las celdas de la grilla dentro de un distrito, es relativamente grande cuando
comparamos las celdas que se encuentran cerca al ecuador con las más
alejadas. Por ejemplo, en América Latina donde se presentan latitudes
mucho mayores que en África, la diferencia resultante en la predicción
de las densidades de población utilizando valores de accesibilidad ajustados
y no ajustados, alcanza hasta ocho personas más por km cuadrado. Las
imágenes de la densidad poblacional, se crean de las celdas de la grilla
con el total de personas dividido por el área real en km cuadrados de
dichas celdas.
La evaluación de la confiabilidad de este método de interpolación es dificil, pues no se tiene un grupo de datos de población con una alta resolución (e.g. conteos en las diferentes áreas), que permita ser usado como patrón de referencia. Para la base de datos de Asia, se llevó a cabo un experiemto simple que consistió en interpolar las cifras de población a nivel de estado para la India. El total de población resultante para cada distrito pudo entonces ser comparado con los datos reales correspondientes. Las diferencias mostradas son aceptables en aquellas regiones relativamente homogéneas, pero obviamente son muy grandes en zonas donde la población se encuentra muy dispersa, como por ejemplo en las altas montañas y en las regiones desérticas. Estos mismos resultados podrían esperarse para África. El modelo funcionará mucho mejor en la medida en que tengamos datos administrativos más detallados, dispongamos de mejores datos de población y mientras las poblaciones se hallen distribuidas de una manera más homogénea.
American Association for the Advancement of Science. (2002) AAAS Atlas of Population and Environment. http://atlas.aaas.org/.
Bongaarts, J. (1996) Population pressure and the food supply system in the developing world. Population and Development Review. 22(3)483-503.
Brockerhoff. (2000) An urbanizing world. Population Bulletin. Washington DC. Population Reference Bureau. 55(3).
Browder, J. O. And B. J. Godfrey. (1997) Rainforest Cities: Urbanization, Development, and Globalization of the Brazilian Amazonia. New York: Columbia University Press.
CELADE (Centro Latinoamericano y Caribeño de Demografía). (2001) Urbanización y evolución de la población urbana de America Latina, 1950-1990. Boletín Demográfico. Santiago de Chile, año 33, No. Especial, base de datos DEPUALC.
Center for International Earth Science Information Network (CIESIN), Columbia University; and Centro Internacional de Agricultura Tropical (CIAT), (2004) Gridded Population of the World (GPW), Version 3. Palisades, NY: Columbia University. Available at http://beta.sedac.ciesin.columbia.edu/gpw.
Center for International Earth Science Information Network (CIESIN), Columbia University; International Food Policy Research Institute (IPFRI), the World Bank; and Centro Internacional de Agricultura Tropical (CIAT), (2004) Global Rural-Urban Mapping Project (GRUMP): Settlement Points. Palisades, NY: CIESIN, Columbia University. Available at: http://beta.sedac.ciesin.columbia.edu/gpw
Center for International Earth Science Information Network (CIESIN), Columbia University; International Food Policy Research Institute (IPFRI), the World Bank; and Centro Internacional de Agricultura Tropical (CIAT), (2004) Global Rural-Urban Mapping Project (GRUMP): Urban Extents. Palisades, NY: CIESIN, Columbia University. Available at: http://beta.sedac.ciesin.columbia.edu/gpw
Center for International Earth Science Information Network (CIESIN), Columbia University; International Food Policy Research Institute (IPFRI), the World Bank; and Centro Internacional de Agricultura Tropical (CIAT), (2004) Global Rural-Urban Mapping Project (GRUMP): Gridded Population of the World, version 3, with Urban Reallocation (GPW-UR). Palisades, NY: CIESIN, Columbia University. Available at: http://beta.sedac.ciesin.columbia.edu/gpw
CEPAL (Comisión Económica para América Latina). (2000). Distribución Espacial y Urbanización en América Latina y El Caribe (DEPUALC). Base de datos, Espina, R. (2000), LC/R 1999. Santiago, Chile.
Cincotta, R., J Wisnewski and R. Engelman. (2000). Human population in the biodiversity hotspots. Nature. 404:990-992.
Cohen, J. (1995), How many people can the Earth support?, Norton, New York.
Cuffaro, N. (1997). Population growth and agriculture in poor countries: a review of theoretical issues and empirical evidence. World Development. 25(7):1151-1163.
Defense Mapping Agency. (1994). Digital Chart of the World, digital data, 1:1 mio sclae, Arc/Info version produced by Environmental Systems Research Instititue.
Deichmann, U. and L. Eklundh (1991). Global digital datasets for land degradation studies: A GIS approach, GRID Case Study Series No. 4, Global Resource Information Database, United Nations Environment Programme, Nairobi.
Deichmann, U. (1994). A medium resolution population database for Africa, Database documentation and digital database, National Center for Geographic Information and Analysis, University of California, Santa Barbara.
Deichmann, U. (1996a). Asia medium resolution population database documentation, Database documentation and digital database prepared in collaboration with UNEP/GRID Geneva for the UNEP/CGIAR Initiative on Use of GIS in Agricultural Research, National Center for Geographic Information and Analysis, University of California, Santa Barbara.
Deichmann, U. (1996b). A review of spatial population database design and modeling, paper prepared for the UNEP/CGIAR Initiative on the Use of GIS in Agricultural Research, National Center for Geographic Information and Analysis, Santa Barbara.
Dijkstra, E.W. (1959). A note on two problems in connexion with graphs, Numerische Mathematik, 1, 269-271.
Dobson, J., E. Bright, P. Coleman, R. Durfee and B. Worley. (2000). Landscan: a global population database for estimating populations at risk. Photogrammetric Engineering and Remote Sensing. 66(7):849-857.
Geertman, S.C.M. and J.R. Ritsema van Eck (1995). GIS and models of accessibility potential: an application in planning, International Journal of Geographic Information Systems. 1:67-80.
Global Environment Facility. (2002). The Challenge of Sustainability: An Action Agenda for the Global Environment. http://gefweb.org/Outreach/outreach-PUblications/MainBook.pdf.
Guzman, J., S. Singh, G. Rodriguez and E. Pantelides. Editors. (1996). The Fertility Transition in Latin America. Oxford: Clarendon Press.
Jones, P.G. and W. C. Bell (1997). Administrative Divisions of Latin America to the Third Order, Digital Version 1.1. CIAT Cali-Colombia.
Livernash, R. and E. Rodenburg. (1998). Population change, resources and the environment. Population Bulletin. Washington DC. Population Reference Bureau. 53(1).
Lonergran, S. (1998). The role of environmental degradation in population displacement. Research Report No. 1. Global Environmental Change and Human Security Project. International Human Dimensions Programme on Global Environmental Change.
Loveland, T.R., Reed, B.C., Brown, J.F., Ohlen, D.O., Zhu, J, Yang, L., and Merchant, J.W., (2000). Development of a Global Land Cover Characteristics Database and IGBP DISCover from 1-km AVHRR Data. International Journal of Remote Sensing, v. 21, no. 6/7, p. 1,303-1,330.
Loveland, T.R., Estes, J.E., and Scepan, J., (1999). Introduction: Special Issue on Global Land Cover Mapping and Validation. Photogrammetric Engineering and Remote Sensing, v. 65, no. 9, p. 1011-1012.
Lutz, W., W. Sanderson and S. Scherbov. (2001). The end of world population growth. Nature. 412:543-545.
Martin, P. and J. Widgren. (1996). International migration: a global challenge. Population Bulletin. Population Reference Bureau. Washington DC. 51(1).
Merrick, Thomas. (1991). Population pressures in Latin America. Population Bulletin. Population Reference Bureau. Washington DC. 41(3).
O'Neill, Brian and Deborah Balk. (2001). Projecting Future World Population. Population Bulletin. Population Reference Bureau. Washington DC. 56(3).
Population Division of the United Nations Secretariat. (1998). United Nations world population projection to 2150. Population and Development Review. 24(1)183-189.
Simoneau, K. (1990). South American Population Censuses Since Independence: An Annotated Bibliography of Secondary Sources. Seminar on the Acquisition of Latin American Library Materials. University of Wisconsin-Madison. Madison, Wisconsin (HB3558 S56).
Rogers, A. (1985). Regional population projection models, Sage, Beverly Hills.
Tobler, W., U. Deichmann, J. Gottsegen and K. Maloy (1995). The global demography project, Technical Report 95-6, NCGIA, Santa Barbara.
United Nations (1998), Principles and recommendations for population and housing censuses, revision 1, Department for Economic and Social Information and Policy Analysis, Statistics Division, New York.
United Nations (2005), World population prospects. The 2004 revision, Department for Economic and Social Information and Policy Analysis, Statistics Division, New York.
United Nations (2003), World urbanization prospects. The 2003 revision, Department for Economic and Social Information and Policy Analysis, Statistics Division, New York.
U.S. Bureau of the Census (2004), Countries of the World - Census dates, International Programs Center, Population Division, Washington, D.C.
United Nations Environment Program. (2000. Latin America and Caribbean Population Database Documentation. On-line at UNEP North America website: http://grid2.cr.usgs.gov/globalpop/lac/intro.html/
Van Lindert, P. and O. Verkoren. Editors. (1997). Small Towns and Beyond: Rural Transformation and Small Urban Centres in Latin America. Amsterdam: Thela Publishers.
Para Israel, las cifras de población estuvieron disponibles en el Statistical Yearbook of Israel 1991, para varios años. En la tabla siguiente se muestra el total de población para seis distritos de Israel, en cuatro años diferentes. En las últimas tres columnas aparecen los totales estimados de población, basados en la tasa promedio de crecimiento annual entre cada uno de los tres primeros años y 1990. La escogencia de la tasa de crecimiento tiene, obviamente, un efecto considerable en el estimado resultante. Aun admitiendo la especial naturaleza de la dinámica poblacional de Israel, debido a la política de inmigración del país (la más probable explicación para la alta tasa de crecimiento entre 1989 y 1990), existe una fuerte dependencia de los datos estimados con relación a los datos que se utilizan como entrada.
| Distrito | Total de Población(`000)1 | Tasa anual de crecimiento (porcentaje) |
Estimados resultantes (`000) para 1995 con base en la tasa | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1985 | 1987 | 1989 | 1990 | 85-90 | 87-90 | 89-90 | 85-90 | 87-90 | 89-90 | |
| Jerusalem | 506 | 533 | 556 | 578 | 2.66 | 2.70 | 3.88 | 660 | 662 | 702 |
| Northern | 707 | 732 | 763 | 805 | 2.60 | 3.17 | 5.36 | 917 | 943 | 1052 |
| Haifa | 593 | 601 | 613 | 656 | 2.02 | 2.92 | 6.78 | 726 | 759 | 921 |
| Central | 889 | 928 | 970 | 1032 | 2.98 | 3.54 | 6.20 | 1198 | 1232 | 1407 |
| Tel Aviv | 1015 | 1027 | 1044 | 1095 | 1.52 | 2.14 | 4.77 | 1181 | 1218 | 1390 |
| Southern | 511 | 526 | 542 | 574 | 2.33 | 2.91 | 5.74 | 645 | 664 | 765 |
1 Fuente: Central Bureau of Statistics (1991), Statistical Abstract of Israel 1991, Jerusalem
| Región | Área (km2) | Número de Unidades | Resolución Media en km. | Número de Personas por unidad1 | Pob. 19602 | Pob. 19702 | Pob. 19802 | Pob. 19902 | Pob. 20002 |
|---|---|---|---|---|---|---|---|---|---|
| LAC | 20,469,646 | 18317 | 33 | 29 | 218,575 | 285,194 | 362,209 | 443,749 | 522,928 |
| North America | 1,962,007 | 2415 | 29 | 41 | 36,940 | 50,611 | 68,046 | 84,296 | 100,088 |
| Caribbean | 234,222 | 393 | 24 | 95 | 20,425 | 24,832 | 29,216 | 33,824 | 37,457 |
| Central America | 517,692 | 4584 | 11 | 8 | 12,781 | 17,286 | 22,673 | 28,504 | 35,950 |
| South America | 17,755,725 | 10925 | 40 | 32 | 148,429 | 192,465 | 242,274 | 297,125 | 349,433 |
| País | Área (km2) | Código ISO |
Número de Unidades | Resolución Media en km. | Número de personas por unidad1 | Pob. 19602 | Pob. 19702 | Pob. 19802 | Pob. 19902 | Pob. 20002 |
|---|---|---|---|---|---|---|---|---|---|---|
| Aruba | 189 | ABW | 1 | 14 | 92 | 49 | 57 | 60 | 66 | 92 |
| Anguilla | 83 | AIA | 1 | 9 | 11 | 6 | 7 | 7 | 9 | 11 |
| Netherlands Antilles | 736 | ANT | 2 | 19 | 88 | 135 | 159 | 174 | 191 | 176 |
| Argentina | 2779454 | ARG | 499 | 75 | 74 | 20616 | 23962 | 28094 | 32581 | 36896 |
| Antigua And Barbuda | 444 | ATG | 2 | 15 | 38 | 55 | 66 | 63 | 63 | 76 |
| Bahamas | 13362 | BHS | 16 | 29 | 19 | 110 | 170 | 210 | 255 | 301 |
| Belize | 22290 | BLZ | 6 | 61 | 40 | 93 | 123 | 144 | 186 | 242 |
| Bolivia | 1087732 | BOL | 100 | 104 | 83 | 3351 | 4212 | 5355 | 6669 | 8317 |
| Brasil | 8518834 | BRA | 5508 | 39 | 32 | 72742 | 95989 | 121615 | 149394 | 173858 |
| Barbados | 441 | BRB | 1 | 21 | 266 | 231 | 239 | 249 | 257 | 266 |
| Chile | 750612 | CHL | 290 | 51 | 53 | 7643 | 9570 | 11174 | 13179 | 15412 |
| Colombia | 1142845 | COL | 1069 | 33 | 39 | 16857 | 22561 | 28447 | 34970 | 42120 |
| Costa Rica | 51381 | CRI | 82 | 25 | 48 | 1334 | 1821 | 2347 | 3076 | 3929 |
| Cuba | 111634 | CUB | 169 | 26 | 66 | 6976 | 8483 | 9645 | 10537 | 11125 |
| Cayman Islands | 279 | CYM | 3 | 10 | 13 | 9 | 10 | 17 | 26 | 40 |
| Dominica | 769 | DMA | 10 | 9 | 8 | 60 | 71 | 74 | 72 | 78 |
| Domincan Republic | 48351 | DOM | 30 | 40 | 276 | 3231 | 4424 | 5718 | 7090 | 8265 |
| Ecuador | 247399 | ECU | 956 | 16 | 13 | 4439 | 5970 | 7961 | 10272 | 12306 |
| Guadeloupe | 1797 | GLP | 11 | 13 | 39 | 275 | 320 | 327 | 391 | 430 |
| Grenada | 325 | GRD | 1 | 18 | 102 | 90 | 94 | 90 | 96 | 102 |
| Guatemala | 108705 | GTM | 329 | 18 | 34 | 4139 | 5418 | 7012 | 8894 | 11166 |
| French Guyana | 83634 | GUF | 21 | 63 | 8 | 32 | 48 | 68 | 116 | 164 |
| Guyana | 211244 | GUY | 10 | 145 | 74 | 569 | 709 | 761 | 729 | 744 |
| Honduras | 111911 | HND | 3693 | 6 | 2 | 1894 | 2592 | 3568 | 4867 | 6424 |
| Haiti | 26876 | HTI | 10 | 52 | 794 | 3803 | 4520 | 5453 | 6867 | 7939 |
| Jamaica | 11060 | JAM | 14 | 28 | 185 | 1629 | 1869 | 2133 | 2369 | 2585 |
| Saint Kitts and Nevis | 277 | KNA | 2 | 12 | 20 | 51 | 45 | 43 | 41 | 40 |
| St. Lucia | 620 | LCA | 1 | 25 | 154 | 90 | 104 | 118 | 138 | 154 |
| Mexico | 1962007 | MEX | 2415 | 29 | 41 | 36940 | 50611 | 68046 | 84296 | 100088 |
| Montserrat | 103 | MSR | 1 | 10 | 4 | 12 | 12 | 12 | 11 | 4 |
| Martinique | 1146 | MTQ | 1 | 34 | 386 | 282 | 325 | 326 | 360 | 386 |
| Nicaragua | 127976 | NIC | 144 | 30 | 34 | 1617 | 2228 | 3067 | 3960 | 4959 |
| Panama | 74974 | PAN | 67 | 33 | 44 | 1126 | 1506 | 1949 | 2411 | 2950 |
| Peru | 1297712 | PER | 1895 | 26 | 14 | 9931 | 13193 | 17324 | 21753 | 25952 |
| Puerto Rico | 8985 | PRI | 78 | 11 | 49 | 2360 | 2716 | 3197 | 3528 | 3835 |
| Paraguay | 400339 | PRY | 228 | 42 | 24 | 1842 | 2350 | 3114 | 4219 | 5470 |
| El Salvador | 20455 | SLV | 263 | 9 | 24 | 2578 | 3598 | 4586 | 5110 | 6280 |
| Surinam | 146755 | SUR | 10 | 121 | 43 | 290 | 372 | 356 | 402 | 434 |
| Turks And Caicos | 548 | TCA | 1 | 23 | 19 | 6 | 6 | 8 | 12 | 19 |
| Trinidad and Tobago | 5202 | TTO | 30 | 13 | 43 | 843 | 971 | 1082 | 1215 | 1285 |
| Uruguay | 177038 | URY | 19 | 97 | 176 | 2538 | 2808 | 2914 | 3106 | 3342 |
| St. Vincent | 453 | VCT | 1 | 21 | 116 | 81 | 90 | 100 | 109 | 116 |
| Venezuela | 912128 | VEN | 320 | 53 | 76 | 7579 | 10721 | 15091 | 19735 | 24418 |
| British Virgin Islands | 166 | VGB | 4 | 6 | 5 | 8 | 10 | 11 | 17 | 21 |
| U.S. Virgin Islands | 374 | VIR | 3 | 11 | 37 | 33 | 64 | 99 | 104 | 111 |
1 Cifras de Población dadas en miles para el año 2000
2 Estimados (en miles) del World Population Prospects: The 2004 Revision, de marzo de 2005.
| Tabla de los atributos de los polígonos | ||
|---|---|---|
| Posición | Item | Descripción |
| 17 | SQKM | Área del polígono |
| 21 | ADMSQKM | Área de la unidad administrativa (suma de SQKM) |
| 25 | CODE | L-Continente, IS-Isla, IW-Cuerpo de agua continental |
| 28 | ADMINID | Unidad Administrativa (ver abajo) |
| 32 | COUNTRY | Identificación ISO de tres letras para cada país |
| 35 | NAME1 | Nombre de la primera unidad a nivel sub-nacional |
| 60 | NAME2 | Nombre de la segunda unidad a nivel sub-nacional ('N.A.' si no está disponible) |
| 85 | NAME3 | Nombre de la tercera unidad a nivel sub-nacional ('N.A.' si no está disponible) |
| 110 | NAME4 | Nombre de la cuarta unidad a nivel sub-nacional ('N.A.' si no está disponible) |
| 135 | NAME5 | Nombre de la quinta unidad a nivel sub-nacional ('N.A.' si no está disponible) |
| 160 | DEMOFLAG | 1 para el polígono mayor perteneciente a una unidad administrativa, 0 para los demás (ver abajo) |
| 162 | P60 | Total estimado de población 1960 |
| 166 | P70 | Total estimado de población 1970 |
| 170 | P80 | Total estimado de población 1980 |
| 174 | P90 | Total estimado de población 1990 |
| 180 | P00 | Total estimado de población 2000 |
| Tabla de los atributos de los arcos | ||
| 29 | FEATURE | 0 - Límite a nivel Internacional 1 - Límite a nivel de la primera unidad administrativa 2 - Límite a nivel de la segunda unidad administrativa 3 - Límite a nivel de la tercera unidad administrativa 9 - Límite con "polígono externo" administrativa |
ADMINID - consta de
código de 3-dígitos de NU para cada país + código
de 2 dígitos de la primera unidad administrativa + código de
2 dígitos de la segunda unidad administrativa + código de 2
dígitos de la tercera unidad administrativa + código de 2 dígitos
de la cuarta unidad administrativa + ódigo de 2 dígitos de la
Quinta unidad administrativa.
Para generar los códigos sub-nacionales, las unidades administrativas fueron: (a) numeradas secuencialmente con base en los listados oficiales de los censos publicados - si existían -, o (b) ordenados alfabéticamente.
DEMOFLAG - indica el mayor (i.e., el más grande) de los polígonos en los casos en que la unidad administrativa conste de más de un polígono. Para todos los demás polígonos que pertenezcan a una misma unidad adminstrativa, la información de los atributos se repite en la tabla. En consecuencia, para la construcción de una tabla de frecuencias o de cualquier cálculo estadístico, es necesarioo seleccionar los polígonos con FLAG =1, para evitar duplicación en los conteos.
Notas
Para los países que no aparecen especificados en la lista
de abajo:
| Spatial data | Population data |
|---|---|
| Atlas de Suelos de la República Argentina. Inta y la Fundación Argentina. | Provincia segun departamento. Poblacion censada en 1991 y 2001 y variacion intercensal aboluta y ralativa 1991-2001. Censo Nacional de Poblacion, Hogares y Viviendas del ano 2001. Instituto Nacional de Estadistica Y Censos Argentina. http://www.indec.mecon.ar/webcenso/index.asp |
| Spatial data | Population data |
|---|---|
| Mapa de la Regionalización de la República de Guatemala. Ministerio de Agricultura. Escala 1:750000. Copia heliográfica. | Central Statistical Office, Ministry of Finance. National Population and Housing Census 2000 http://www.belize.gov.bz/features/cso/ |
| Spatial data | Population data |
|---|---|
| Instituto Geográfico Militar. Mapa de la República de Bolivia. Escala 1:1500000. Proyección Cónica Comforme de Lambert. | Instituto Nacional de estadística, INE. Indicadores Socio-demográficospor Provincias. Censo de 1992. La Paz, Bolivia |
| Spatial data | Population data |
|---|---|
| CD-Rom from IGBP | Instituto Brasileiro de Geografia y Estatística, IBGE.Censo Demográfico 2000 |
| Spatial data | Population data |
|---|---|
| Digital Chart of the World | Cayman Census, 1989 http://www.columbiagazetteer.org/ and Cayman Census, 1999 http://www.caymanislands.ky/tour_guide/population.asp |
| Spatial data | Population data |
|---|---|
| Instituto Nacional de Estadísticas. Sub. Depto. Cartografía. Dpto. Geografía y Censos. 1981. Con la nueva Diivisón Política. Escala 1:3000000 and Mapa Caminero Geografico y turistico de Chile Inupal. 1987. Escala 1: 1.400.000 Codigo Ciat 782 gbbg 1989 - 782 fb 198; prepared by CIAT. | Instituto Nacional de Estadisctica, INE. 1992 and 2002; http://www.ine.cl; refinements made at CIESIN using http://www.ine.cl/cd2002/index.php, an intercative map showing 1992 and 2002 population by municipio |
| Spatial data | Population data |
|---|---|
| Instituto Geográfico "Agustín Codazzi". 1995. Mapa digitalizado por el DANE. Plancha 1:500000 | Departamento Administrativo Nacional de Estadística, DANE."República de Colombia: Panorama Colombiano." http://www.sin.com.co/clientes/DANE/censo93.html |
| Spatial data | Population data |
|---|---|
| Instituto Geográfico Nacional. 1984. Mapa de Provincias y Cantones. Escala 1:1500000 | Dirección General de Estadística y Censos. 1996. Instituto Nacional de Estadística y Censos, INEC. IX Censo Nacional de Población y Vivivenda del 2000. http://www.meic.go.cr/. |
| Spatial data | Population data |
|---|---|
| Cuba Político administrativo. Escala: 1:1250000. Proyección sin información . Editado en 1997. | Population for 1991 from Census of Cuba 1991 - digital data from the
UN Statistics Division's Software Development Project. Population 2000 came from the Anuario Estadistico de Cuba 2000 from the Oficina Nacional de Estadisticas. |
| Spatial data | Population data |
|---|---|
| Digital Chart of the World | Commonwealth of Dominica. Demographic Statistics, No.2, 1996. Central Statistical Office, Ministry of Finance. Roseau, Dominica. |
| Spatial data | Population data |
|---|---|
| Mapa de la República Dominicana. Confeccionado por el Instituto Geográfico Universitario. 1985. Escala 1:600000. | 2002 population data obtained from Dominican Republic National Office
of Statistics Census for 2002 http://www.one.gov.do/datos2002.htm,
i.e., Oficina Nacional de Estadísticas, VIII Censo Nacional de Población
y Vivienda 2002, (Resultados Preliminares). 1993 population data from: CENSOS NACIONAL DE POBLACIO Y VIVIENDA 1993 http://www.one.gov.do/datos.htm |
| Spatial data | Population data |
|---|---|
| Instituto Nacional de Estadística y Censos. Divisón Político Administrativa
de la República del Ecuador. 1993. Planchas y escalas: Provincia de Sucumbios 1:250000 Provincia de Napo 1:250000 Provincia de Pastaza 1:250000 Prov. de Morona Santiago 1:250000 Prov. de Zamora Chinchipe 1:250000 Prov. de Esmeraldas 1:250000 Prov. de Manabi 1:250000 Prov. de Los Ríos 1:250000 Prov. de Guayas 1:250000 Prov. El Oro 1:250000 Prov. de Galápagos 1:500000 Prov. de Carchi 1:250000 Prov. de Imbabura 1:250000 Prov. de Pichincha 1:250000 Prov. de Cotopaxi 1:250000 Prov. de Tungurahua 1:250000 Prov. de Bolívar 1:250000 Prov. de Chimborazo 1:250000 Prov. de Canar 1:250000 Prov. de Azuay 1:250000 Prov. de Loja 1:250000 |
Instituto Nacional de Estadística y Censos, INEC. 1990 |
| Spatial data | Population data |
|---|---|
| Dirección General de Estadística y Censos, Unidad de Cartografía 1987. Mapa de la República de El Salvador, División Político-Administrativa. Copia Heliográfica. Escala 1:200000 | Dirección General de Estadística y Censos. 1992. |
| Spatial data | Population data |
|---|---|
| Mapa de la Regionalización de la República de Guatemala. Ministerio de Agricultura. Escala 1:750000. Copia Heliográfica | 1994 population from: Instituto Nacional de Estadística, INE. 1996.
República de Guatemala. Características Generales de Población y Habitación.
Guatemala. 2002 population from: Republica de Guatemala. Instituto Nacional de Estadistica. Censo Nacionales XI de Poblacion y VI de Habitacion 2002, http://www.censos.gob.gt/ |
| Spatial data | Population data |
|---|---|
| Guyana North-East Sheet compiled in the Cartographic Division. Lands Department, Ministry of Agriculture | Bureau of Statistics. 1991 |
| Spatial data | Population data |
|---|---|
| Institute Geographique National.Carte Touristique Guyane au 1:500000. 1995 | Institute National de la Statistique et des Etudes Economiques, INSEE, 1995. Tableux Economiques Régionaux. Guyane, 1995, and 1999; http://www.recensement.insee.fr. |
| Spatial data | Population data |
|---|---|
| Boundary data sources: (Información digital) Chemonics International 1998. | Institut Haitien de Statistique et de Informatique, IHSI. 1997. |
| Spatial data | Population data |
|---|---|
| SERNA, Honduras | 1988 population from Dirección General de Estadística y Censos. 1988.
2001 population from Censo Nacional de Poblacion y Vivienda 2001, Instituto Nacional de Estadistica, downloaded from http://www.ine-hn.org/ |
| Spatial data | Population data |
|---|---|
| Jamaica. Published by the Survey Department, Jamaica Government 1982. Escala 1:250000. | The Statistical Institute of Jamaica, 1991. Population Census 2001 Jamaica Vol 1 Country Report and Preliminary Report for 1991's Urban /Rural |
| Spatial data | Population data |
|---|---|
| Mapa Geoestadístico. Secretaría de Programación y Presupuesto (S.P.P.). 1981. Escala 1:1000000 con información del X Censo de Población y Vivienda de 1980. 4 hojas: Norte, Centro, Noroeste y Sudeste. | 1990 and 2000 municipio data downloaded from SIMBAD, 28 April 2004 (Toda la Base de Datos Municipal INEGI from http://www.inegi.gob.mx/inegi/default.asp). |
| Spatial data | Population data |
|---|---|
| Mapa de la División Político Administrativa, 1997. Proyección Transversal de Mercator. Escala: 1:750000 | Instituto Nacional de Estadística y Censos, INEI.1996. Censos Nacionales 1995, Cifras Oficiales finales. Managua, Nicaragua. |
| Spatial data | Population data |
|---|---|
| República de Panamá. Mapa Político. Instituto Geográfico Nacional "TOMMY GUARDIA". 1998. Escala: 1:1000000 | Dirección de Estadística y Censos, DEC. X Censo Nacional de Población
y VI de Vivienda 2000. http://contraloria.gob.pa/
Direccion de Estadistica y Censo Censos nacionales de Poblacion Y Vivienda 13 Mayo de 1990 Cifras Preliminarios Junio de 1990 |
| Spatial data | Population data |
|---|---|
| Dirección General de Estadística, Encuesta y Censos. FNUAP-PNUD. 1995.
Atlas de Necesidades Básicas Insatisfechas del Paraguay. Planchas y escalas:
Dpto. Canindeyu 1:700000 Dpto. Amambay 1:850000 Dpto. Neembucu 1:750000 Dpto. Central 1:400000 Dpto. Paraguari 1:600000 Dpto. Misiones 1:600000 Dpto. Itapua 1:900000 Dpto. Caazapa 1:650000 Dpto. Alto Paraná 1:800000 Dpto. Caaguazu 1:800000 Dpto. Guaira 1:420000 Dpto. Cordillera 1:400000 Dpto. San Pedro 1:800000 Dpto. Concepción 1:750000 Dpto. Occidental 1:300000 |
Dirección Nacional de Estadística, Encuestas y Censos, DGEEC, 1995.
Atlas del Paraguay 1995. Necesidades Básicas Insatisfechas, Asunción,
Paraguay. Dirección General de Estadística, Encuestas y Censos, 2002. |
| Spatial data | Population data |
|---|---|
| Instituto Geográfico Nacional. 1984. Mapa Físico Político del Perú. Proyección Mercator Transversa. Escala: 1:1000000. 4 hojas. | Instituto Nacional de Estadística e Informática, INEI. "Población nominalmente censada, por áreas urbana y rural y sexo, según Provincia y Distrito: 1993" http://contraloria.gob.pa/ |
| Spatial data | Population data |
|---|---|
| US Census Bureau | US Census Bureau: 1990 Decennial Census and 1997 Population Estimates |
| Spatial data | Population data |
|---|---|
| 1- Distrikt Nickerie 1:300000 Hoja C.B.L. 469-1 2- Distrikt Coronie 1:200000 Hoja C.B.L. 469-2 3- Distrikt Saramacca 1:200000 Hoja C.B.L. 469-3 4- Distrikt Wanica 1:50000 Hoja C.B.L. 469-4 5- Distrikt Commewijne 1:200000 Hoja C.B.L. 469-6 6- Distrikt Marowijne 1:200000 Hoja C.B.L. 469-7 7- Distrikt Para 1:200000 Hoja C.B.L. 469-8 8- Distrikt Paramaribo 1:25000 Hoja C.B.L. 469-5 9- Distrikt Brokopondo 1:200000 Hoja C.B.L. 469-9 10- Distrikt Sipaliwini 1:1000000 Hoja C.B.L. 469-10Q |
General Bureau of Statistics, 1999 |
| Spatial data | Population data |
|---|---|
| Republic of Trinidad and Tobago Central Statistical Office (CSO), 1988. | Ward level data for 1990, Central Statistical Office, 1990 Population
and Housing Census, Vol II(2), Demographic Report, 1994 Port of Spain.
The 1990 county and 2000 county and wards within St George County obtained from the Trinidad and Tobago Central Statistics Office 2000 Census Table 8 http://www.cso.gov.tt/statistics/cssp/census2000/default.asp. |
| Spatial data | Population data |
|---|---|
| Servicio Geográfico Militar. 1992. Mapa de la República Oriental del Uruguay, carta geográfica división política. Escala: 1:500000 Prepared by CIAT. | Instituto Nacional de Estadística, INE, 1994. Anuario Estadístico. Montevideo, Uruguay. |
| Spatial data | Population data |
|---|---|
| Oficina Central de Estadística e Informática Presidencia de la República. Dirección de Geografía y Cartografía. 1993. Mapa de la División Política Territorial de Venezuela. Copia Heliográfica. | Oficina Central de Estadística e Informática, OCEI, 1991. Tiempo de
resultados, primeros resultados Censo 1990. Caracas, Venezuela. Instituto Nacional de Estadística, Republica Bolivariana de Venezuela. XIII Censos General de Poblacio y Vivienda, Primeros Resultados, Censo 2001. Downloaded from http://www.ine.gov.ve/ine/censo/fichascenso/fichacenso.asp |




* Lugares Poblados del Center for International Earth Science Information Network (CIESIN), Columbia University; International Food Policy Research Institute (IPFRI), the World Bank; y del Centro Internacional de Agricultura Tropical (CIAT), (2004) Global Rural-Urban Mapping Project (GRUMP): Gridded Population of the World, version 3, with Urban Reallocation (GPW-UR). Palisades, NY: CIESIN, Columbia University.
El Centro Internacional de Agricultura Tropical (CIAT) apoya el desarrollo de Bases de Datos de División Administrativa y Poblacionales, para América Latina y El Caribe a través de su Laboratorio de Sistemas de Información Geográfica y del proyecto de Uso de la Tierra. Silvia Elena Castaño, Rosalba López, Alexander Cuero, Carlos Nagles, Elizabeth Barona and Peter Jones desarrollaron muchos de los datos básicos en este proyecto. Agradecemos a Liliana Pérez por su trabajo en la verificación de la calidad de la información. Estamos agradecidos por la colaboraión de la Comisión Económica de las Naciones Unidad para América Latina (CEPAL), del Banco Mundial y de todos los países de América Latina por su apoyo en este proyecto. Esta versión de la Base de Datos fue hecha en estrecha cooperación con el Centro Internacional de la Red de Información para la Ciencia de la Tierra (CIESIN) Gridded Population of the World, Version 3 project. El Banco Interamericano de Desarrollo (IADB), el Programa de las Naciones Unidas para el Medio Ambiente (UNEP/GRID Sioux Falls, UNEP/GRID Arendal), el Instituto Mundial de Recursos Naturales (WRI), y el Instituto Internacional de Investigación para Políticas Alimentarias (IFPRI), proporcionaron fondos y apoyo a lo largo de este proyecto.